Konuşmacının Dudak Hareketlerinden Farklı Dillerdeki Konuşmaları Tanıyabilen Bir Model
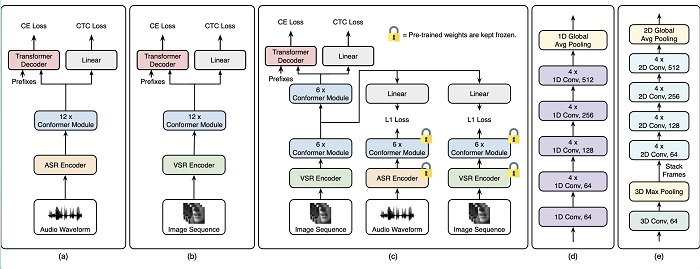
Fotoğraf : Temel ASR modeli(a), temel VSR modeli(b) ve tahmine dayalı yardımcı görevlerle önerilen model(c), a’daki ASR kodlayıcının yapısı(d), b’deki VSR kodlayıcının yapısı(e). Son yıllarda, derin öğrenme teknikleri çok sayıda dil ve görüntü işleme görevinde dikkate değer sonuçlar elde etmiştir. Bu, yalnızca konuşmacının dudak hareketlerini analiz ederek konuşma içeriğinin tanımlanmasını...