Konuşmacının Dudak Hareketlerinden Farklı Dillerdeki Konuşmaları Tanıyabilen Bir Model
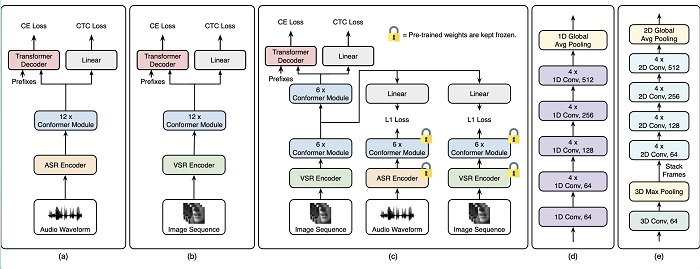
Fotoğraf : Temel ASR modeli(a), temel VSR modeli(b) ve tahmine dayalı yardımcı görevlerle önerilen model(c), a’daki ASR kodlayıcının yapısı(d), b’deki VSR kodlayıcının yapısı(e).
Son yıllarda, derin öğrenme teknikleri çok sayıda dil ve görüntü işleme görevinde dikkate değer sonuçlar elde etmiştir. Bu, yalnızca konuşmacının dudak hareketlerini analiz ederek konuşma içeriğinin tanımlanmasını gerektiren görsel konuşma tanımayı (VSR) içermektedir.
Bazı derin öğrenme algoritmaları, VSR görevlerinde son derece umut verici sonuçlar elde etse de, mevcut eğitim veri setlerinin çoğu yalnızca İngilizce konuşmayı içerdiğinden, bunlar öncelikle İngilizce konuşmayı algılamak üzere eğitilmiştir. Bu, potansiyel kullanıcı tabanlarını İngilizce konuşulan ortamlarda yaşayan veya çalışan kişilerle sınırlamaktadır.
Imperial College London’daki araştırmacılar yakın zamanda VSR görevlerini birden fazla dilde gerçekleştirebilen yeni bir model geliştirdiler. Nature Machine Intelligence’ta yayınlanan bir makalede tanıtılan bu modelin, daha önce önerilen ve çok daha büyük veri kümeleri üzerinde eğitilmiş bazı modellerden daha iyi performans gösterdiği bulunmuştur.
“Görsel konuşma tanıma (VSR), doktora tezimin ana konularından biriydi,” demiştir araştırmayı yürüten Imperial College mezunu Pingchuan Ma. TechXplore’a şunları söylemiştir: “Çalışmalarım sırasında, örneğin, görsel-işitsel konuşma tanıma için görsel bilgiyi sesle nasıl birleştireceğimi ve katılımcıların baş duruşundan bağımsız olarak görsel konuşmayı nasıl tanıyacağımı keşfetmek gibi çeşitli konular üzerinde çalıştım. Mevcut literatürün büyük bir çoğunluğunun sadece İngilizce konuşma ile ilgilendiğini fark ettim.”
Ma ve meslektaşları tarafından yapılan son çalışmanın temel amacı, İngilizce dışındaki dillerdeki konuşmaları konuşmacıların dudak hareketlerinden tanımak için bir derin öğrenme modeli geliştirmek ve ardından performansını İngilizce konuşmayı tanımak için eğitilmiş diğer modellerinkiyle karşılaştırmaktı. Araştırmacılar tarafından oluşturulan model, geçmişte diğer ekipler tarafından tanıtılanlara benzer, ancak bazı hiper parametreleri optimize edilmiş, veri kümesi arttırılmış ve ek kayıp fonksiyonları kullanılmıştır.
Ma, “Aynı modelleri VSR modellerini diğer dillerde eğitmek için kullanabileceğimizi gösterdik,” şeklinde açıklamıştır. “Modelimiz, herhangi bir özellik çıkarmadan ham görüntüleri girdi olarak almakta ve ardından VSR görevlerini tamamlamak için bu görüntülerden hangi yararlı özelliklerin çıkarılacağını otomatik olarak öğrenmektedirt. Bu çalışmanın ana yeniliği, bir modeli görsel konuşma tanımayı gerçekleştirmek için eğitiyoruz ve ayrıca bazı ek veri arttırma yöntemleri ve kayıp işlevlerini ilave ediyoruz.”
İlk değerlendirmelerde, Ma ve meslektaşları tarafından oluşturulan model, daha az orijinal eğitim verisi gerektirmesine rağmen, çok daha büyük veri kümeleri üzerinde eğitilen diğer VSR modellerini geride bırakarak oldukça iyi performans göstermiştir. Ancak beklenildiği gibi, temel olarak eğitim için mevcut olan daha küçük veri kümeleri nedeniyle İngilizce konuşma tanıma modelleri kadar iyi performans göstermemiştir.
Ma, “Literatürdeki mevcut eğilim olan daha büyük veri kümeleri veya daha büyük modeller kullanmak yerine, modeli dikkatli bir şekilde tasarlayarak birden fazla dilde en gelişmiş sonuçlara ulaştık,” demiştir. “Başka bir deyişle, bir modelin nasıl tasarlandığının, performansının boyutunu artırmak veya daha fazla eğitim verisi kullanmaktan daha az önemli olmadığını gösterdik. Bu, potansiyel olarak araştırmacıların VSR modellerini iyileştirmeye çalışma biçiminde bir değişikliğe yol açabilir.”
Ma ve meslektaşları, aynı modelin daha büyük sürümlerini kullanmak veya hem pahalı hem de zaman alan ek eğitim verileri toplamak yerine derin öğrenme modellerini dikkatlice tasarlayarak VSR görevlerinde son teknoloji performanslara ulaşılabileceğini göstermiştir. Yaptıkları çalışma gelecekte diğer araştırma ekiplerine İngilizce dışındaki dillerde konuşmaları dudak hareketlerinden etkili bir şekilde tanıyabilen alternatif VSR modelleri geliştirme konusunda ilham verebilir.
Ma, “İlgilendiğim ana araştırma alanlarından biri, VSR modellerini mevcut (yalnızca sesli) konuşma tanıma ile nasıl birleştirebileceğimizdir,” diye eklemiştir. “Ben özellikle bu modellerin gürültüye bağlı olarak hangi modele güvenmesi gerektiğini nasıl öğrenebileceği ile ilgileniyorum. Diğer bir deyişle, gürültülü bir ortamda görsel-işitsel bir model daha çok görsel akışa, ancak ağız bölgesi net bir şekilde görüntülenemediğinde ise ses akışına daha fazla güvenmelidir. Mevcut modellerin, bir kez eğitildiklerinde ortamdaki değişikliklere uyum sağlayamaları zor olmaktadır.”
Kaynak: techxplore.com



